
Photon: A Databricks-native vectorized query engine
Ashish Shukla
10/29/20233 min read

In this blog we are going to discuss a new optimized query engine integrated with spark. But prior to that lets discuss about some internals about the spark architecture. Spark follows the hierarchy where action breaks down to job then stages and lastly tasks. A partition is assigned to the tasks for further execution. Now the question comes that how spark decides that what data should go where and what to do with that. For that it uses something called “Catalyst Optimizer”.
This catalyst optimizer has five main steps: Input, Analysis, Logical Plan, Physical Plan and Code generation.


Let’s say we are submitting the code having some SQL queries and dataframes. As a next step, spark creates a plan without any fact checking called ”Unresolved Logical Plan”. Proceeding forward, Spark start the basic investigation to see what metadata it has, whether it has relevant data for that or not. This is called Logical Plan. Once Spark is done with investigation, then spark further optimize it. Lets uderstand it with example: your code is using filter operation which filters a small amount of data, then spark will take only that much data instead of using whole data. This stage is called “Optimized Logical Plan”. Now, spark choose best way of any aggregation or transformation defined under code under the physical plan. This optimized physical plan is converted into the Scala code which later converted to Java byte code. Lastly all of this turn into the RDD.
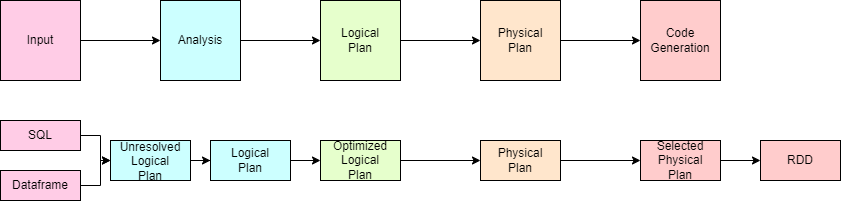
This whole spark architecture is based on JVM(Java Virtual Machine). This current architecture is having some present days problems which are as follows:
1. Performance improvement requires good understanding of internal knowledge of JVM and also requires a lot of effort in terms of hit and trials.
2. Dataframe in Spark is still row-Based where most of the file formats are columnar.
3. Code-generation for debug can be nightmare where most time goes in building custom telemetry instead of real debug of code.
To overcome such problem, databricks has introduced a more optimized SQL engine called “Photon”. As an official definition of databricks documentation “Photon is a high-performance Azure Databricks-native vectorized query engine that runs your SQL workloads and DataFrame API calls faster to reduce your total cost per workload”. Photon uses C++ instead of Scala which makes it comparatively faster which means no more messy code generation. There are following advantages od using Photon:
Support for SQL and equivalent DataFrame operations with Delta and Parquet tables.
Accelerated queries that process data faster and include aggregations and joins.
Faster performance when data is accessed repeatedly from the disk cache.
Robust scan performance on tables with many columns and many small files.
Faster Delta and Parquet writing using UPDATE, DELETE, MERGE INTO, INSERT, and CREATE TABLE AS SELECT, including wide tables that contain thousands of columns.
Replaces sort-merge joins with hash-joins.
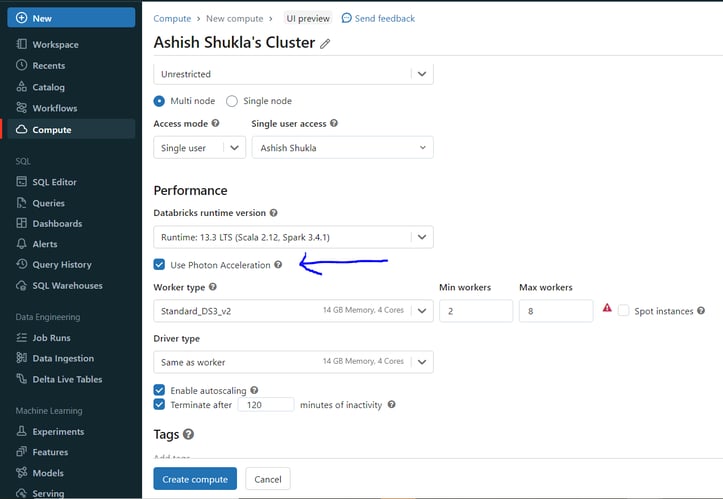
How to enable Photon in the databricks cluster:
Click on "Use Photon Acceleration" option in the cluster configuation of compute page in Azure databricks portal.
Limitations:
Structured Streaming: Photon currently supports stateless streaming with Delta, Parquet, CSV, and JSON. Stateless Kafka and Kinesis streaming is supported when writing to a Delta or Parquet sink.
Photon does not support UDFs or RDD APIs.
Photon doesn’t impact queries that normally run in under two seconds.
Features not supported by Photon run the same way they would with Databricks Runtime.
Note: Photon instance types consume DBUs at a different rate than the same instance type running the non-Photon runtime which can incur some extra cost.

Contact us
Whether you have a request, a query, or want to work with us, use the form below to get in touch with our team.
